Solving multidimensional PDEs in pytorch
Solving multi-dimensional partial differential equations (PDE’s) is something I’ve spent most of my adult life doing. Most of them are somewhat similar to the heat equation:
\[\nabla^2 u = \frac{du}{dt}\]where u is some function of possibly many variables. Liouville’s equation, the Schrodinger equation, The Fokker-Plank equation etc. etc. are all equations of this form. Usually one spends as much time trying to derive useful properties from u, as one spends solving u.
Many properties of \(u(\vec{x},t)\) of interest are actually derivatives or integrals, perhaps even of the solution with respect to parameters of the equation or solver or vice versa. To this end, it’s extraordinarily useful to be able to solve this equation in such a way that u is differentiable with respect to these parameters and vice-versa.
For example, to calibrate the parameters \(\mu (X_{t},t), \sigma (X_{t},t)\) of a multidimensional stochastic differential equation: \(dX_{t}=\mu (X_{t},t)\,dt+\sigma (X_{t},t)\,dW_{t}\) one would often like the conditional density \(P(X_t | X_{t-1})\) which is available as a solution to a Fokker-Plank equation:
\[{\frac {\partial P(\mathbf {x} ,t)}{\partial t}}=-\sum _{i=1}^{N}{\frac {\partial }{\partial x_{i}}}\left[\mu _{i}(\mathbf {x} ,t)P(\mathbf {x} ,t)\right]+\sum _{i=1}^{N}\sum _{j=1}^{N}{\frac {\partial ^{2}}{\partial x_{i}\,\partial x_{j}}}\left[D_{ij}(\mathbf {x} ,t)P(\mathbf {x} ,t)\right]\]with respect to a delta function initial condition. The applications to finance should now be more obvious, this is how one calibrates Heston or more sophisticated models. Usually one would need hundreds of lines of code to optimize \(\mu (X_{t},t), \sigma (X_{t},t)\), it’s actually the subject of innumerable theses, and several luminaries of econometrics are famous for simply applying Galerkin methods to optimize these parameters.
In all my years of solving PDEs… I have never really come across a simpler way to solve them than what I’m about to show (<100 lines!). This also results in a solution which is differentiable. It’s all quick, and very general. The only limitation is that derivatives above 2 would be impractical, but besides that very high dimensions are solvable.
A solution of the heat equation in pytorch.
The basic idea here is to use the incredible approximation properties of neural networks as a “more better” Galerkin method. Simply sample a very flexible differentiable function and force it to obey conditions in batches.
- step 1: build a flexible neural ansatze.
- step 2: implement the PDE.
- step 3: minimize error of the PDE under the ansatze.
- step 4: visualize.
I will show two ansatze, a simple feed-forward network, and a feed-forward Gaussian Mixture model. If you don’t know much about Gaussian mixtures, you can just look at the simplicity of the neural density. Both simply model a function \(\rho(t,x)\). The advantage of the Gaussian Mixture is that normalization is automatically enforced, and it could easily be used for importance sampling. Ideally one could use normalizing flows or any other sophisticated method to generate a flexible distribution.
class Neural_Density(torch.nn.Module):
"""
A neural model of a time dependent probability density on
a vector valued state-space.
ie: rho(t,{x_0, x_1, ... x_{state_dim}})
for now, I'm not even enforcing normalization.
could with a gaussian mixture or whatever.
"""
def __init__(self, state_dim, hidden_dim = 64):
super(Neural_Density, self).__init__()
self.input_dim = state_dim+1 # self.register_buffer('input_dim',state_dim+1)
self.state_dim = state_dim
self.net = tch.nn.Sequential(
tch.nn.Linear(self.input_dim, hidden_dim),
tch.nn.Softplus(),
tch.nn.Linear(hidden_dim, 1),
tch.nn.Softplus(), # density is positive.
)
def forward(self,t,x):
# Just evaluate the probability at the argument.
return self.net(tch.cat([t.unsqueeze(-1),x],-1)).squeeze()
class Reshape(tch.nn.Module):
def __init__(self, shp):
super(Reshape, self).__init__()
self.shape = shp
def forward(self, x):
return x.view(self.shape)
class Gaussian_Mixture_Density(tch.nn.Module):
def __init__(self, state_dim,
m_dim=1,
hidden_dim = 16,
):
"""
A network which parameterically
produces gaussian output with feed-forwards
that parameterize the mixture.
"""
super(Gaussian_Mixture_Density, self).__init__()
# Rho(x,y) is the density parameterized by t
input_dim=1
output_dim=state_dim
self.output_dim = output_dim
self.m_dim = m_dim
mixture_dim = output_dim*m_dim
self.n_corr = int((self.output_dim*(self.output_dim-1)/2.))
self.sftpls = tch.nn.Softplus()
self.sftmx = tch.nn.Softmax(dim=-1)
self.corr_net = tch.nn.Sequential(
# tch.nn.Dropout(0.1),
tch.nn.Linear(input_dim, hidden_dim),
tch.nn.Tanh(),
tch.nn.Linear(hidden_dim, self.n_corr*m_dim),
Reshape((-1, m_dim, self.n_corr))
)
self.std_net = tch.nn.Sequential(
# tch.nn.Dropout(0.1),
tch.nn.Linear(input_dim, hidden_dim),
tch.nn.SELU(),
tch.nn.Linear(hidden_dim, mixture_dim),
tch.nn.Softplus(10.),
Reshape((-1, m_dim, self.output_dim))
)
self.mu_net = tch.nn.Sequential(
# tch.nn.Dropout(0.1),
tch.nn.Linear(input_dim, hidden_dim),
tch.nn.Tanh(),
tch.nn.Linear(hidden_dim, mixture_dim),
Reshape((-1, m_dim, self.output_dim))
)
self.pi_net = tch.nn.Sequential(
# tch.nn.Dropout(0.1),
tch.nn.Linear(input_dim, hidden_dim),
tch.nn.SELU(),
tch.nn.Linear(hidden_dim, m_dim),
tch.nn.Tanh(),
tch.nn.Softmax(dim=-1)
)
super(Gaussian_Mixture_Density, self).add_module("corr_net",self.corr_net)
super(Gaussian_Mixture_Density, self).add_module("std_net",self.std_net)
super(Gaussian_Mixture_Density, self).add_module("mu_net",self.mu_net)
super(Gaussian_Mixture_Density, self).add_module("pi_net",self.pi_net)
def pi(self, x):
return self.pi_net(x)
def mu(self, x):
return self.mu_net(x)
def L(self, x):
"""
Constructs the lower diag cholesky decomposed sigma matrix.
"""
batch_size = x.shape[0]
L = tch.zeros(batch_size, self.m_dim, self.output_dim, self.output_dim)
b_inds = tch.arange(batch_size).unsqueeze(1).unsqueeze(1).repeat(1, self.m_dim, self.output_dim).flatten()
m_inds = tch.arange(self.m_dim).unsqueeze(1).unsqueeze(0).repeat(batch_size, 1, self.output_dim).flatten()
s_inds = tch.arange(self.output_dim).unsqueeze(0).unsqueeze(0).repeat(batch_size, self.m_dim,1).flatten()
L[b_inds, m_inds, s_inds, s_inds] = self.std_net(x).flatten()
if self.output_dim>1:
t_inds = tch.tril_indices(self.output_dim,self.output_dim,-1)
txs = t_inds[0].flatten()
tys = t_inds[1].flatten()
bb_inds = tch.arange(batch_size).unsqueeze(1).unsqueeze(1).repeat(1, self.m_dim, txs.shape[0]).flatten()
mt_inds = tch.arange(self.m_dim).unsqueeze(1).unsqueeze(0).repeat(batch_size, 1, txs.shape[0]).flatten()
xt_inds = txs.unsqueeze(0).unsqueeze(0).repeat(batch_size, self.m_dim, 1).flatten()
yt_inds = tys.unsqueeze(0).unsqueeze(0).repeat(batch_size, self.m_dim, 1).flatten()
L[bb_inds, mt_inds, xt_inds, yt_inds] = self.corr_net(x).flatten()
return L
def get_distribution(self, x):
pi_distribution = tch.distributions.Categorical(self.pi(x))
GMM = tch.distributions.mixture_same_family.MixtureSameFamily(pi_distribution,
tch.distributions.MultivariateNormal(self.mu(x),
scale_tril=self.L(x)))
return GMM
def forward(self, t, x):
return self.get_distribution(t.unsqueeze(-1)).log_prob(x).exp()
def rsample(self, t, sample_shape = 128):
"""
returns samples from the gaussian mixture (samples are added last dimension)
ie: batch X dim X samp
"""
samps_ = self.get_distribution(t).sample(sample_shape=[sample_shape])
samps = samps_.permute(1,2,0)
return samps
def mean(self,t):
return self.get_distribution(t.unsqueeze(-1)).mean
def std(self,t):
return tch.sqrt(self.get_distribution(t.unsqueeze(-1)).variance)Next we define a module which checks that the heat equation is satisfied on a random batch of points. These could be chosen more cleverly by importance sampling etc. but this is sufficient to show the correct behavior.
class Neural_Heat_PDE(torch.nn.Module):
def __init__(self, state_dim = 2, batch_size = 64, initial_function=None,
max_time = 10.):
"""
Defines losses to ensure Neural_Density (rho) solves a PDE
which is hard-coded inside. (eventually to be Fokker-Plank)
drho(t,x)/dt = ...
The PDE is evaluated on a grid randomly chosen.
"""
super(Neural_Heat_PDE, self).__init__()
self.state_dim = state_dim
self.batch_size = batch_size
self.max_time = max_time
if (initial_function is None):
self.initial_function = lambda X : torch.distributions.multivariate_normal.MultivariateNormal(tch.zeros(self.state_dim),
0.02*tch.eye(self.state_dim)).log_prob(X).exp()
def x_t_sample_batch(self):
x = torch.distributions.multivariate_normal.MultivariateNormal(tch.zeros(self.state_dim),
5.*tch.eye(self.state_dim)).rsample([self.batch_size])
t = torch.distributions.uniform.Uniform(0.,self.max_time).rsample([self.batch_size])
return x,t
def initial_loss(self, rho):
x,t = self.x_t_sample_batch()
y0 = self.initial_function(x)
fy0 = rho(tch.zeros(x.shape[0]) , x)
return torch.pow(fy0 - y0,2.0).sum()
def kernel_loss(self,rho):
"""
simply the heat equation...
"""
x_,t_ = self.x_t_sample_batch()
x = tch.nn.Parameter(x_,requires_grad=True)
t = tch.nn.Parameter(t_,requires_grad=True)
f = rho(t, x)
dfdt = torch.autograd.grad(f.sum(), t, create_graph=True, allow_unused=True)[0].sum()
d2fdx2 = tch.einsum('ijij->',torch.autograd.functional.hessian(lambda x : rho(t_, x).sum() ,
x, create_graph=True))
differential = 0.5*d2fdx2
return torch.pow(-dfdt + differential,2.0).sum()
def forward(self,rho):
"""
both these losses are evaluated over the batch'd grid
defined by the initial condition.
"""
return self.initial_loss(rho)+self.kernel_loss(rho)Finally we merely optimize these losses:
# Solve the heat equation!
# rho = Neural_Density(2)
rho = Gaussian_Mixture_Density(2)
heat_equation = Neural_Heat_PDE()
optimizer = torch.optim.Adam(rho.parameters(), lr=5e-3)
# first anneal the initial condition.
for step in range(100):
il = heat_equation.initial_loss(rho)
loss = il
if step%10==0:
print(f"{step} init_loss {il.cpu().detach().item():.4f} kern_loss {kl.cpu().detach().item():.4f}")
loss.backward(retain_graph=False)
tch.nn.utils.clip_grad_norm_(rho.parameters(),10.)
optimizer.step()
optimizer.zero_grad()
for step in range(1000):
il = heat_equation.initial_loss(rho)
kl = heat_equation.kernel_loss(rho)
loss = il+kl
if step%10==0:
print(f"{step} init_loss {il.cpu().detach().item():.4f} kern_loss {kl.cpu().detach().item():.4f}")
loss.backward(retain_graph=False)
tch.nn.utils.clip_grad_norm_(rho.parameters(),10.)
optimizer.step()
optimizer.zero_grad()Now note that the correct solution of the heat equation in two dimensions results in the standard deviations of a growing Gaussian blob, growing with \(\sim \sqrt(t)\)
Here’s what images look like from our differentiable solution:
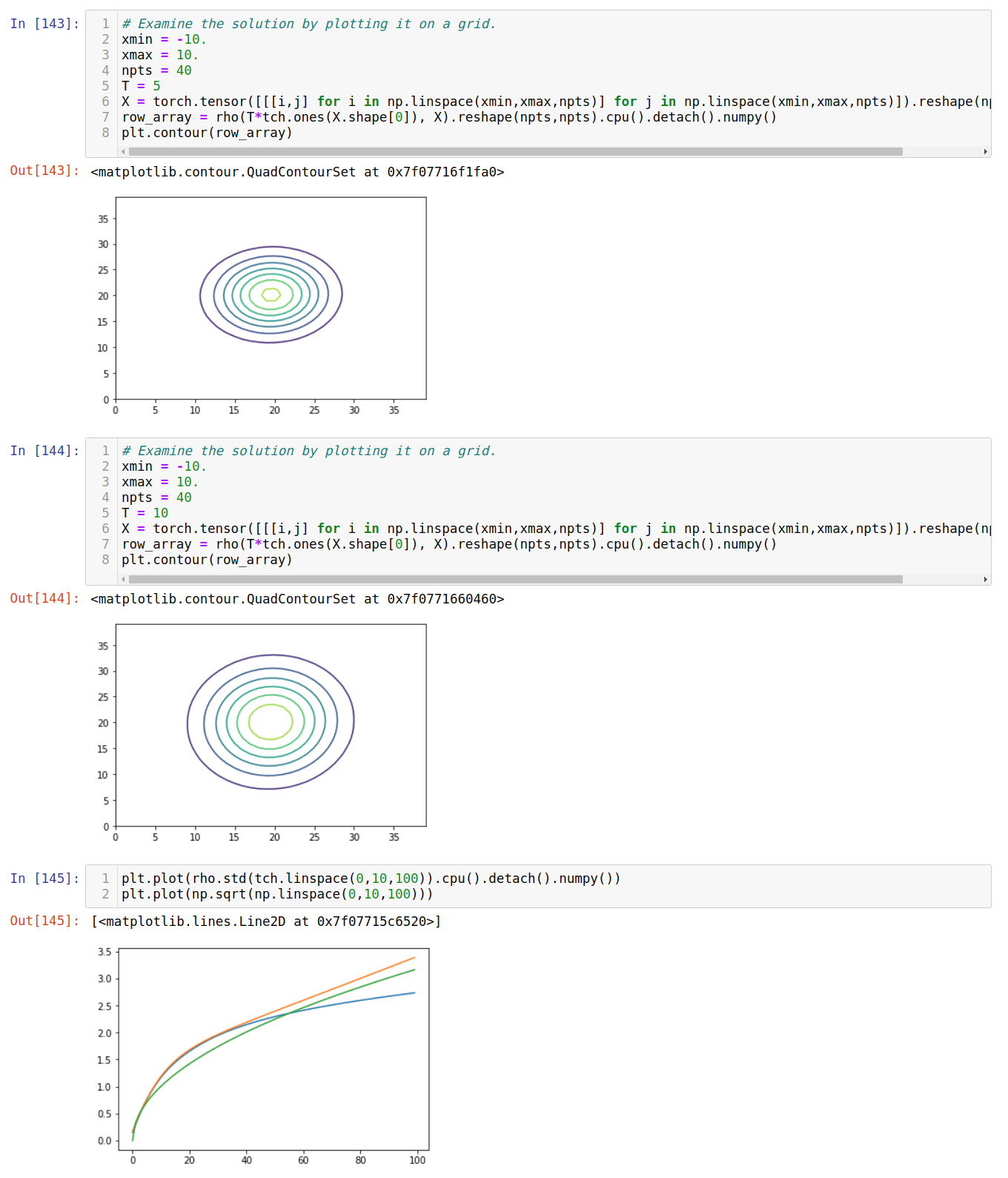 Not too shabby for such little work and time and so much generality.
Not too shabby for such little work and time and so much generality.